
.svg)




.webp)
Exploring the Frontiers of AI with Qwen 2.5 and DeepSeek R1: A Comparative Guide

In today's digital era, artificial intelligence (AI) is not just a buzzword but a fundamental technology transforming various sectors, from education and healthcare to finance and entertainment. Among the AI advancements, language models like Qwen 2.5 and DeepSeek R1 are pivotal, driving innovations that influence how we interact with technology daily. This blog aims to demystify these complex tools, making the information accessible and understandable for everyone, regardless of their technical background.
Understanding Language Models
Imagine having a conversation with someone who not only speaks multiple languages but can also assist you with everything from writing an email to solving a math problem. That's essentially what advanced language models do—they understand and generate human-like text based on the data they've been trained on. These models can converse, compose documents, offer customer support, and even write code, mimicking human intelligence in increasingly sophisticated ways.
Introducing Qwen 2.5 and DeepSeek R1
Qwen 2.5, developed by Alibaba Cloud, and DeepSeek R1, from TechFront AI, are among the latest advancements in this field. Each has been designed to excel in specific aspects of language processing, but they also share common goals: to enhance efficiency, accuracy, and user-friendliness in AI-driven tasks.
Key Features at a Glance
Before diving deeper, let's outline the key features of each model:
- Qwen 2.5 is renowned for its multilingual capabilities, understanding over 100 languages. It excels in logical reasoning and complex problem-solving, making it a versatile tool for a wide range of applications.
- DeepSeek R1 focuses on semantic understanding, which helps it comprehend the deeper meaning behind texts. It's highly secure and integrates smoothly with various software, making it ideal for professional environments where accuracy and data privacy are crucial.
A Closer Look at Performance and Capabilities
Both models bring unique strengths to the table:
- Performance: Qwen 2.5 is designed to handle complex, multi-step tasks efficiently. On the other hand, DeepSeek R1 is optimized for high accuracy in understanding and generating technical and professional texts.
- Language Support: While both models support numerous languages, Qwen 2.5's extensive language support is particularly beneficial for global businesses that need to interact with a diverse clientele.
- Customization and Integration: DeepSeek R1 stands out with its customization options, which are crucial for industries requiring tailored AI solutions, such as healthcare or legal services. Meanwhile, Qwen 2.5 integrates seamlessly within Alibaba’s extensive ecosystem, enhancing user experience for customers of Alibaba Cloud services.
Security and Ethical Considerations
Security is paramount in today's digital world, especially when handling sensitive information. DeepSeek R1 emphasizes robust security protocols, making it suitable for sectors where data breaches can have significant consequences. Qwen 2.5, while also secure, focuses on ethical AI development, aiming to prevent biases and ensure fairness in AI interactions.

The graph above visually compares Qwen 2.5 and DeepSeek R1 across various features such as performance, language support, customization, integration, and security. Each model's strengths are highlighted, providing a clear snapshot of where each model excels.
Understanding Advanced AI Parameters and Architectures
Language models like Qwen 2.5 and DeepSeek R1 rely on complex structures and parameters to process and generate language. Here’s an explanation of some key terms and concepts:
1. Mixture of Experts (MoE):
Definition: MoE is a machine learning technique that involves multiple specialist models (experts) and a gating network that decides which expert to use for a given task. This allows the system to handle a wide variety of tasks efficiently by leveraging the expertise of different models for different kinds of data or queries.
Application: In language models, MoE can enhance performance by allowing the model to use resources more efficiently. For example, one expert might be better at understanding natural language queries, while another might excel at generating code.
2. Transformer Architecture:
Definition: Transformer is a type of neural network architecture that has become the backbone of modern language models. It uses mechanisms called attention and self-attention to process words in relation to all other words in a sentence, rather than one at a time sequentially. This allows the model to capture complex linguistic structures and context more effectively.
Application: Both Qwen 2.5 and DeepSeek R1 utilize Transformer architectures to manage the extensive data processing required for understanding and generating human-like text. This architecture is particularly effective in handling long-range dependencies in text, such as resolving references to subjects mentioned much earlier in a conversation or document.
3. Tokenization:
Definition: Tokenization is the process of converting text into smaller units (tokens), which can be as small as words or subwords. This process is critical for preparing data for processing by a language model.
Application: Effective tokenization is crucial for language models to accurately interpret and generate text. It impacts everything from the model’s understanding of language nuances to its ability to generate coherent and contextually appropriate responses.
4. Fine-Tuning:
Definition: Fine-tuning is a training approach where a pre-trained model is further trained (fine-tuned) on a smaller, specific dataset. This is done to adapt the model to particular tasks or industries without losing the general capabilities learned during initial extensive training.
Application: Both Qwen 2.5 and DeepSeek R1 can be fine-tuned for specific applications, such as legal document analysis or technical support chats, enhancing their effectiveness in specialized fields.
5. Ethical AI:
Definition: Ethical AI refers to the practice of designing, developing, and deploying AI with ethical considerations in mind to ensure the technology benefits people without causing harm. This involves considerations of fairness, privacy, transparency, and accountability.
Application: Both models incorporate ethical AI principles to minimize biases and ensure that the AI’s interactions are fair and just. This is particularly important in applications like hiring, lending, or any other domain where biased AI decisions could lead to unfair outcomes.
Why Does This Matter to You?
Understanding the capabilities of these AI tools is more than an academic exercise—it's about recognizing how such technologies can impact your daily life, work, and future opportunities. Whether you're a business owner looking to deploy AI for customer service, a developer eager to integrate AI into your projects, or simply an AI enthusiast, knowing the strengths and limitations of different models helps you make informed decisions.
Final Thoughts
Qwen 2.5 and DeepSeek R1 are at the forefront of AI technology, each pushing the boundaries of what's possible with machine learning. By choosing the right tool for your needs, you can leverage these advancements to enhance productivity, improve accuracy, and even inspire innovation within your endeavors.
As we continue to explore these powerful AI models, the potential for transformative applications seems limitless. Engaging with this technology not only prepares us for a future dominated by AI but also equips us with the knowledge to shape that future responsibly.
Revolutionizing Large Language Models with Mixture-of-Experts Architecture
In the rapidly evolving landscape of artificial intelligence, Tencent has unveiled a game-changing innovation: Hunyuan A13B. This open-source large language model represents a paradigm shift in how we approach AI efficiency, combining the power of 80 billion parameters with the computational efficiency of just 13 billion active parameters through its revolutionary Mixture-of-Experts (MoE) architecture.
Technical Specifications
The model employs a sophisticated fine-grained MoE architecture with one shared expert and 64 non-shared experts, activating 8 experts per forward pass. It features 32 layers, SwiGLU activations, and Grouped Query Attention (GQA) for efficient memory utilization.
Unique Selling Propositions
Performance Comparison
Benchmark Performance Visualization
Key Use Cases
Competitive Advantages
Efficiency Comparison
(Performance per Billion Parameters)
Future Implications
Hunyuan A13B represents a significant step forward in democratizing AI technology. Its efficient architecture and open-source nature are likely to:

Hunyuan A13B stands as a testament to the power of innovative architecture in AI development. By combining the efficiency of Mixture-of-Experts with dual-mode reasoning and a massive context window, Tencent has created a model that challenges the conventional wisdom that bigger always means better.
For organizations looking to implement advanced AI capabilities without the computational overhead of traditional large language models, Hunyuan A13B offers a compelling solution. Its open-source nature, combined with state-of-the-art performance, positions it as a game-changer in the AI landscape.
Hunyuan A13B is available now on Hugging Face and can be deployed using popular frameworks like Transformers. Join the growing community of developers leveraging this powerful model for innovative AI applications.
Transforming Text into Cinematic Reality with Native Audio Integration
The Next Frontier of AI Video Generation
In May 2025, Google DeepMind unveiled Veo 3, a groundbreaking AI video generation model that has fundamentally changed how we think about artificial content creation. This state-of-the-art system doesn't just generate videos—it creates complete audiovisual experiences that blur the line between AI-generated content and reality.
Key Statistics & Performance Metrics
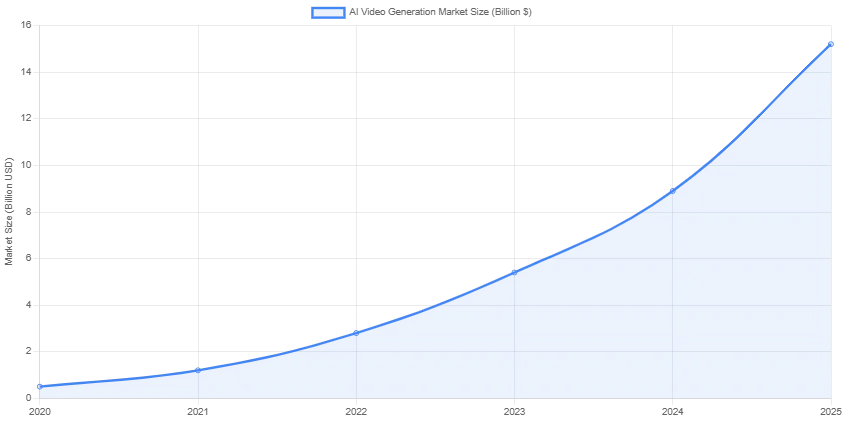
AI Video Generation Market Evolution
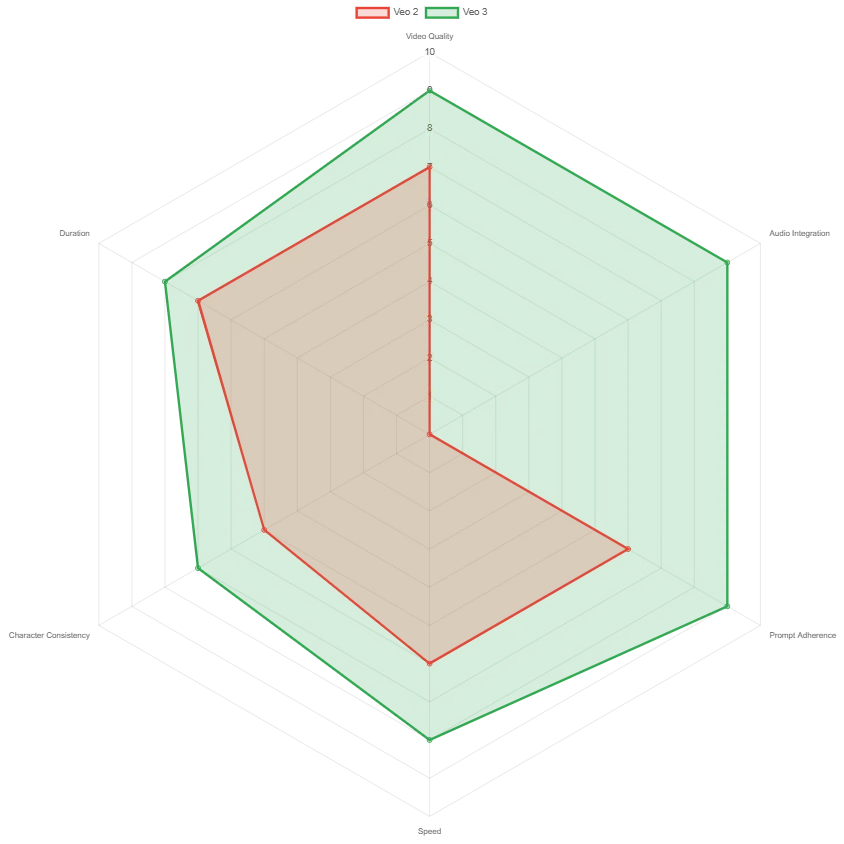
Veo Model Comparison: Key Capabilities
Revolutionary Features
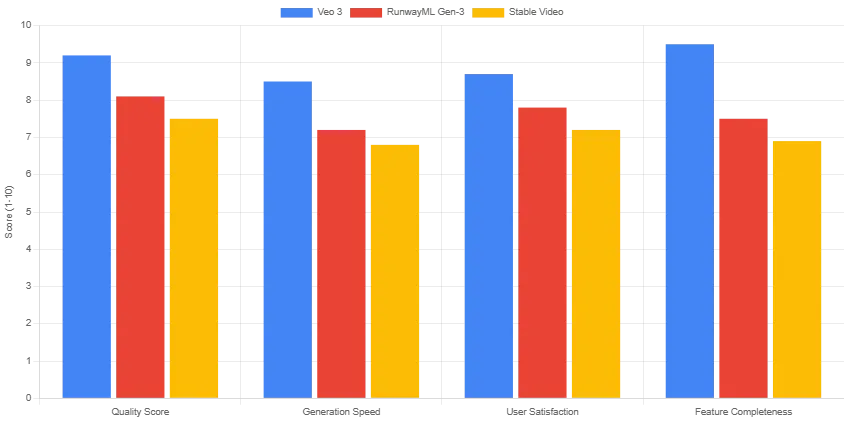
Performance Benchmarks: Veo 3 vs Competitors
Technical Specifications
Development Timeline
Google AI Plan Comparison
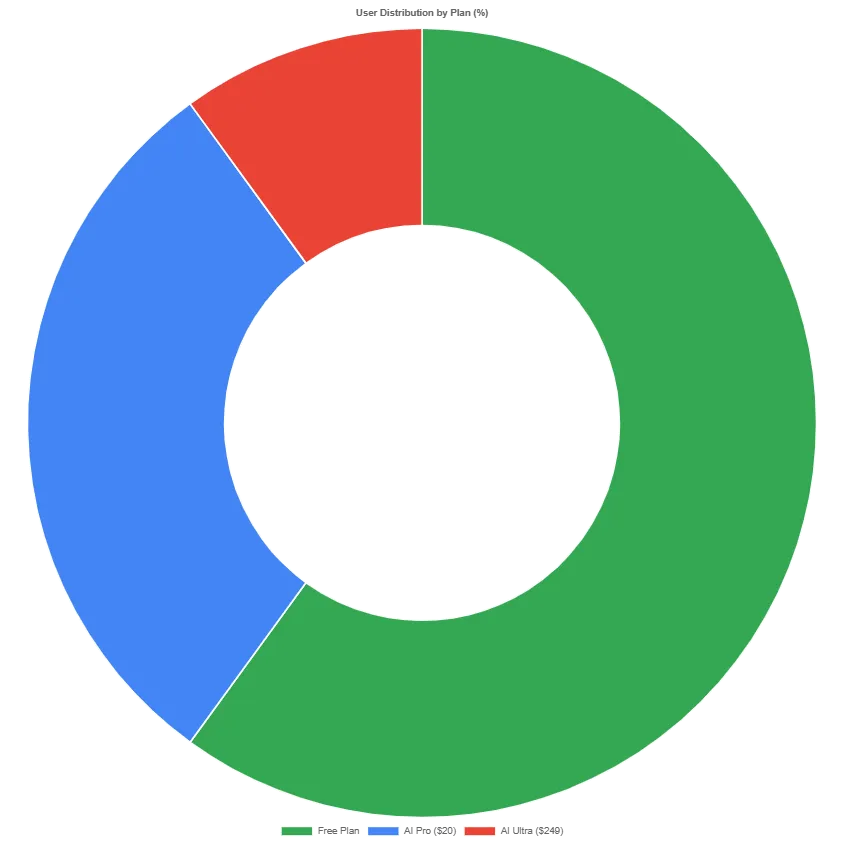
Plan Details

User Adoption Rate (First Month)
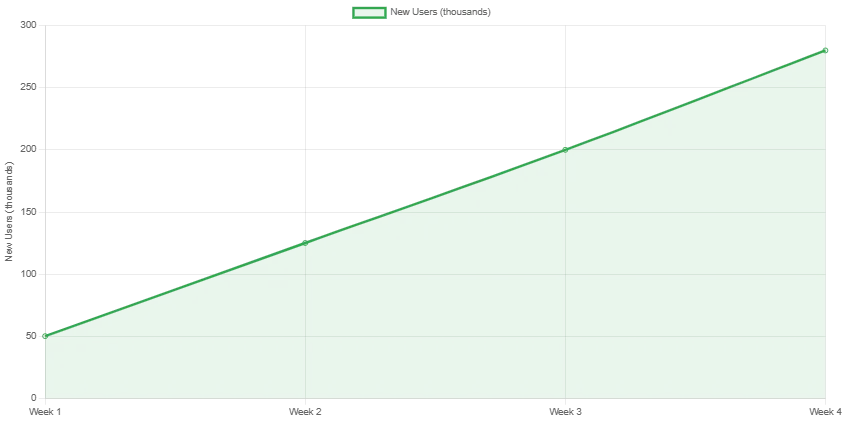
The response to Veo 3 has been unprecedented in the AI video generation space. Within just three weeks of launch, the tool has:
- Generated over 1 million videos across all user tiers
- Achieved 85% user satisfaction in early beta testing
- Reduced video production costs by 70% for small content creators
- Sparked industry-wide discussions about AI authenticity and regulation
Challenges and Limitations
Future Implications & Industry Impact
Veo 3 represents more than just a technological advancement—it signals a fundamental shift in content creation. The integration of native audio generation sets a new industry standard that competitors will struggle to match.
Predicted Industry Changes:
- Content Creation Democratization: High-quality video production becomes accessible to non-professionals
- Traditional Media Disruption: Lower barriers to entry challenge established production companies
- Regulatory Response: Governments likely to introduce stricter AI content labeling requirements
- Educational Revolution: Personalized video content transforms online learning
- Marketing Evolution: Brands can create unlimited variations of video advertisements
Conclusion
While challenges remain around cost, accessibility, and ethical implications, Veo 3 has undeniably set the new standard for AI video generation. As we move forward, the question isn't whether AI will transform video content creation—it's how quickly the industry will adapt to this new reality.
The future of video content creation is here, and it's more accessible, more powerful, and more realistic than ever before.
Most online stores have streamlined their ordering process to just one click. For years, however, the process of canceling an order has gone in the opposite direction: finding a form, typing an email, and waiting for a reply. The legislature is putting an end to this very imbalance—and it will happen soon.
With Directive (EU) 2023/2673, the European Union is amending the Consumer Rights Directive and introducing a mandatory digital withdrawal function. In Germany, it will be implemented through the new Section 356a of the Civil Code (BGB), which will take effect on June 19, 2026—across the EU, uniformly, and without a further transition period. Austria is implementing the same requirements through the Consumer Rights Directive Implementation Act.
To many companies, this sounds like a minor front-end issue. In practice, however, it affects the entire process—from the user interface to customer accounts, CRM, and ERP, all the way through to refunds and audit-proof documentation. Tackling this early on helps avoid a last-minute project under time pressure.
Why bother:
A Response to “Dark Patterns”
In recent years, European regulators have consistently taken action against contractual practices that pressure people into signing agreements while making it unnecessarily difficult for them to exercise their rights. Making a purchase takes seconds—but canceling it has become a test of patience. The new rule levels the playing field. Legal experts call this functional equivalence: The process of getting out of a contract must not be more complicated than the process of entering into it.
Anyone who can enter into a contract online should also be able to cancel it online.
Important to know: The law refers to a “cancellation function,” not literally to a “button.” In practice, this can be a clearly labeled button—or a prominently displayed link, as long as it is just as easy to find. What matters is not the form, but the accessibility.
Who is affected:
Much more than a traditional online store
Many merchants assume that the requirement applies only to pure online stores. The scope is broader: it applies to distance contracts for goods, services, and financial products concluded via an online user interface—that is, via websites as well as apps. Specifically, this includes, among other things:
And it's not just about where a company is headquartered. Providers outside the EU—such as those in Switzerland—are also affected as soon as they specifically target consumers within the European Union.
What Needs to Be Done
Four Requirements, One Process
A link to a PDF or a contact page isn't enough. What's expected is a seamless digital process—simple, transparent, and easy to follow.
One point that is often overlooked: When the feature changes, the required text changes as well. The cancellation policy and privacy policy must be updated—the latter with regard to the newly collected data, its processing, and retention period.
What Many Misjudge
Platform Location
Native function or custom integration?
As the deadline approaches, apps, plugins, and extensions are popping up everywhere. The situation varies depending on the system:
A native platform feature lowers the barrier to entry. But as soon as ERP and CRM integration, automated returns and refunds, custom business logic, multilingual workflows, audit trails, or existing customer portals come into play, a standard app quickly reaches its limits. Larger stores and custom solutions require integrations that fit seamlessly into their processes.
Even though some details of the national implementation are still being worked out, the essentials are clear: The “Cancel” button will be mandatory. It is not an isolated exception, but part of a broader trend toward greater transparency, consumer-friendliness, and digital standards in European commerce. Those who modernize their processes now will not only ensure compliance—but also create a better experience for their own customers.
Here's how Deepware helps
Not just a button. A robust process.
The task is not to incorporate a specific element, but to establish a revocation process that complies with the law and is technically sound. We will prepare your systems for the new requirements in a timely manner.











.svg)




