
.svg)




.webp)
Erkundung der Grenzen der KI mit Qwen 2.5 und DeepSeek R1: Ein vergleichender Leitfaden

Im heutigen digitalen Zeitalter ist künstliche Intelligenz (KI) nicht nur ein Schlagwort, sondern eine grundlegende Technologie, die verschiedene Sektoren verändert, von Bildung und Gesundheitswesen bis hin zu Finanzen und Unterhaltung. Unter den KI-Fortschritten sind Sprachmodelle wie Qwen 2.5 und DeepSeek R1 von zentraler Bedeutung, da sie Innovationen vorantreiben, die beeinflussen, wie wir täglich mit Technologie interagieren. Ziel dieses Blogs ist es, diese komplexen Tools zu entmystifizieren und die Informationen für alle zugänglich und verständlich zu machen, unabhängig von ihrem technischen Hintergrund.
Sprachmodelle verstehen
Stellen Sie sich vor, Sie führen ein Gespräch mit jemandem, der nicht nur mehrere Sprachen spricht, sondern Ihnen auch bei allem helfen kann, vom Schreiben einer E-Mail bis zum Lösen eines Matheproblems. Genau das tun fortgeschrittene Sprachmodelle – sie verstehen und generieren menschenähnlichen Text auf der Grundlage der Daten, mit denen sie trainiert wurden. Diese Modelle können sich unterhalten, Dokumente verfassen, Kundensupport anbieten und sogar Code schreiben und dabei die menschliche Intelligenz auf immer ausgefeiltere Weise nachahmen.
Einführung von Qwen 2.5 und DeepSeek R1
Zu den neuesten Entwicklungen auf diesem Gebiet zählen Qwen 2.5 , entwickelt von Alibaba Cloud, und DeepSeek R1 von TechFront AI. Beide wurden entwickelt, um in bestimmten Aspekten der Sprachverarbeitung zu überzeugen, doch sie verfolgen auch ein gemeinsames Ziel: die Verbesserung von Effizienz, Genauigkeit und Benutzerfreundlichkeit bei KI-gesteuerten Aufgaben.
Wichtige Funktionen auf einen Blick
Bevor wir tiefer ins Detail gehen, wollen wir die Hauptmerkmale jedes Modells skizzieren:
- Qwen 2.5 ist für seine Mehrsprachigkeit bekannt und versteht über 100 Sprachen. Es zeichnet sich durch logisches Denken und komplexe Problemlösungen aus und ist somit ein vielseitiges Werkzeug für eine breite Palette von Anwendungen.
- DeepSeek R1 konzentriert sich auf semantisches Verständnis, wodurch es die tiefere Bedeutung von Texten versteht. Es ist hochsicher und lässt sich problemlos in verschiedene Software integrieren. Damit ist es ideal für professionelle Umgebungen, in denen Genauigkeit und Datenschutz von entscheidender Bedeutung sind.
Ein genauerer Blick auf Leistung und Fähigkeiten
Beide Modelle bringen einzigartige Stärken mit sich:
- Leistung : Qwen 2.5 ist darauf ausgelegt, komplexe Aufgaben mit mehreren Schritten effizient zu bewältigen. DeepSeek R1 hingegen ist für eine hohe Genauigkeit beim Verstehen und Generieren technischer und professioneller Texte optimiert.
- Sprachunterstützung : Beide Modelle unterstützen zahlreiche Sprachen, die umfassende Sprachunterstützung von Qwen 2.5 ist jedoch besonders für globale Unternehmen von Vorteil, die mit einem vielfältigen Kundenstamm interagieren müssen.
- Anpassung und Integration : DeepSeek R1 zeichnet sich durch seine Anpassungsoptionen aus, die für Branchen wie das Gesundheitswesen oder juristische Dienstleistungen von entscheidender Bedeutung sind, die maßgeschneiderte KI-Lösungen benötigen. Gleichzeitig lässt sich Qwen 2.5 nahtlos in das umfangreiche Ökosystem von Alibaba integrieren und verbessert das Benutzererlebnis für Kunden der Alibaba Cloud-Dienste.
Sicherheit und ethische Überlegungen
Sicherheit ist in der heutigen digitalen Welt von größter Bedeutung, insbesondere beim Umgang mit vertraulichen Informationen. DeepSeek R1 legt Wert auf robuste Sicherheitsprotokolle und eignet sich daher für Bereiche, in denen Datenschutzverletzungen erhebliche Folgen haben können. Qwen 2.5 ist zwar ebenfalls sicher, konzentriert sich jedoch auf die ethische KI-Entwicklung mit dem Ziel, Voreingenommenheit zu verhindern und Fairness bei KI-Interaktionen sicherzustellen.

Die obige Grafik vergleicht Qwen 2.5 und DeepSeek R1 visuell anhand verschiedener Merkmale wie Leistung, Sprachunterstützung, Anpassung, Integration und Sicherheit. Die Stärken jedes Modells werden hervorgehoben und bieten einen klaren Überblick darüber, wo jedes Modell herausragt.
Erweiterte KI-Parameter und -Architekturen verstehen
Sprachmodelle wie Qwen 2.5 und DeepSeek R1 basieren auf komplexen Strukturen und Parametern, um Sprache zu verarbeiten und zu generieren. Hier ist eine Erklärung einiger wichtiger Begriffe und Konzepte:
1. Experten-Mix (MoE):
Definition: MoE ist eine maschinelle Lerntechnik, die mehrere spezialisierte Modelle (Experten) und ein Gating-Netzwerk umfasst, das entscheidet, welcher Experte für eine bestimmte Aufgabe verwendet wird. Dadurch kann das System eine Vielzahl von Aufgaben effizient bewältigen, indem es das Fachwissen verschiedener Modelle für unterschiedliche Arten von Daten oder Abfragen nutzt.
Anwendung: In Sprachmodellen kann MoE die Leistung verbessern, indem es dem Modell ermöglicht, Ressourcen effizienter zu nutzen. Beispielsweise kann ein Experte natürlichsprachliche Abfragen besser verstehen, während ein anderer beim Generieren von Code hervorsticht.
2. Transformatorarchitektur:
Definition: Transformer ist eine Art neuronale Netzwerkarchitektur, die zum Rückgrat moderner Sprachmodelle geworden ist. Es verwendet Mechanismen namens Aufmerksamkeit und Selbstaufmerksamkeit, um Wörter im Verhältnis zu allen anderen Wörtern in einem Satz zu verarbeiten, anstatt nacheinander eins nach dem anderen. Dadurch kann das Modell komplexe linguistische Strukturen und Kontexte effektiver erfassen.
Anwendung: Sowohl Qwen 2.5 als auch DeepSeek R1 nutzen Transformer-Architekturen, um die umfangreiche Datenverarbeitung zu bewältigen, die zum Verstehen und Generieren von menschenähnlichem Text erforderlich ist. Diese Architektur ist besonders effektiv beim Umgang mit weitreichenden Abhängigkeiten in Texten, wie z. B. beim Auflösen von Verweisen auf Themen, die in einem Gespräch oder Dokument viel früher erwähnt wurden .
3. Tokenisierung:
Definition: Tokenisierung ist der Prozess der Umwandlung von Text in kleinere Einheiten (Token), die so klein wie Wörter oder Wortteile sein können. Dieser Prozess ist entscheidend für die Vorbereitung der Daten zur Verarbeitung durch ein Sprachmodell.
Anwendung: Eine effektive Tokenisierung ist für Sprachmodelle entscheidend, um Text genau zu interpretieren und zu generieren. Sie wirkt sich auf alles aus, vom Verständnis des Modells für Sprachnuancen bis hin zu seiner Fähigkeit, kohärente und kontextbezogen angemessene Antworten zu generieren.
4. Feinabstimmung:
Definition: Feinabstimmung ist ein Trainingsansatz, bei dem ein vorab trainiertes Modell anhand eines kleineren, spezifischen Datensatzes weiter trainiert (feinabgestimmt) wird. Dies geschieht, um das Modell an bestimmte Aufgaben oder Branchen anzupassen, ohne die allgemeinen Fähigkeiten zu verlieren, die während des anfänglichen, umfassenden Trainings erlernt wurden.
Anwendung: Sowohl Qwen 2.5 als auch DeepSeek R1 können für bestimmte Anwendungen, wie z. B. die Analyse juristischer Dokumente oder technische Support-Chats, feinabgestimmt werden, wodurch ihre Effektivität in Spezialbereichen verbessert wird.
5. Ethische KI:
Definition: Ethische KI bezieht sich auf die Praxis, KI unter Berücksichtigung ethischer Überlegungen zu entwerfen, zu entwickeln und einzusetzen, um sicherzustellen, dass die Technologie den Menschen nützt, ohne Schaden zu verursachen. Dabei geht es um Überlegungen zu Fairness, Datenschutz, Transparenz und Rechenschaftspflicht.
Anwendung: Beide Modelle beinhalten ethische KI-Prinzipien, um Voreingenommenheit zu minimieren und sicherzustellen, dass die Interaktionen der KI fair und gerecht sind. Dies ist besonders wichtig bei Anwendungen wie Personalbeschaffung, Kreditvergabe oder anderen Bereichen, in denen voreingenommene KI-Entscheidungen zu unfairen Ergebnissen führen könnten.
Warum ist das für Sie wichtig?
Das Verständnis der Fähigkeiten dieser KI-Tools ist mehr als eine akademische Übung – es geht darum, zu erkennen, wie sich solche Technologien auf Ihr tägliches Leben, Ihre Arbeit und Ihre zukünftigen Möglichkeiten auswirken können. Egal, ob Sie ein Geschäftsinhaber sind, der KI für den Kundenservice einsetzen möchte, ein Entwickler, der KI in seine Projekte integrieren möchte, oder einfach ein KI-Enthusiast – die Kenntnis der Stärken und Grenzen verschiedener Modelle hilft Ihnen dabei, fundierte Entscheidungen zu treffen.
Abschließende Gedanken
Qwen 2.5 und DeepSeek R1 sind Vorreiter der KI-Technologie und erweitern die Grenzen des Möglichen mit maschinellem Lernen. Indem Sie das richtige Tool für Ihre Anforderungen auswählen, können Sie diese Fortschritte nutzen, um die Produktivität zu steigern, die Genauigkeit zu verbessern und sogar Innovationen in Ihren Bemühungen anzuregen.
Während wir diese leistungsstarken KI-Modelle weiter erforschen, scheint das Potenzial für transformative Anwendungen grenzenlos. Die Beschäftigung mit dieser Technologie bereitet uns nicht nur auf eine von KI dominierte Zukunft vor, sondern gibt uns auch das Wissen, diese Zukunft verantwortungsvoll zu gestalten.
Die meisten Online-Shops haben ihren Bestellprozess auf einen Klick optimiert. Der Widerruf dagegen verlief jahrelang in die andere Richtung: Formular suchen, E-Mail tippen, auf eine Antwort warten. Genau dieses Ungleichgewicht beendet der Gesetzgeber – und zwar bald.
Mit der Richtlinie (EU) 2023/2673 ändert die Europäische Union die Verbraucherrechterichtlinie und führt eine verpflichtende digitale Widerrufsfunktion ein. In Deutschland wird sie über den neuen § 356a BGB umgesetzt, der am 19. Juni 2026 in Kraft tritt – EU-weit, einheitlich und ohne weitere Übergangsfrist. Österreich setzt dieselben Vorgaben über das Verbraucherrechte-Richtlinie-Umsetzungsgesetz um.
Für viele Unternehmen klingt das nach einer Kleinigkeit im Frontend. In der Praxis berührt es die gesamte Kette – von der Benutzeroberfläche über Kundenkonto, CRM und ERP bis zur Rückerstattung und zur revisionssicheren Dokumentation. Wer das früh angeht, vermeidet ein Last-Minute-Projekt unter Zeitdruck.
Warum überhaupt:
Eine Antwort auf „Dark Patterns“
In den vergangenen Jahren sind europäische Aufsichtsbehörden konsequent gegen Gestaltungsmuster vorgegangen, die Menschen zum Abschluss drängen, ihnen die Ausübung ihrer Rechte aber unnötig erschweren. Der Kauf gelingt in Sekunden – der Widerruf wurde zur Geduldsprobe. Die neue Regel macht aus dieser Asymmetrie eine Gleichung. Juristen nennen das funktionale Äquivalenz: Der Weg aus dem Vertrag darf nicht komplizierter sein als der Weg hinein.
Wer einen Vertrag online abschließen kann, soll ihn auch online widerrufen können.
Wichtig zu wissen: Das Gesetz spricht von einer Widerrufsfunktion, nicht wörtlich von einem „Button“. In der Praxis kann das ein klar beschrifteter Button sein – oder ein deutlich hervorgehobener Link, solange er genauso leicht zu finden ist. Entscheidend ist nicht die Form, sondern die Erreichbarkeit.
Wer betroffen ist:
Deutlich mehr als der klassische Online-Shop
Viele Händler nehmen an, die Pflicht treffe nur reine Webshops. Der Anwendungsbereich ist breiter: Sie gilt für Fernabsatzverträge über Waren, Dienstleistungen und Finanzprodukte, die über eine Online-Benutzeroberfläche geschlossen werden – also über Websites ebenso wie über Apps. Konkret betrifft das unter anderem:
Und es geht nicht nur um den Unternehmenssitz. Auch Anbieter außerhalb der EU – etwa aus der Schweiz – sind betroffen, sobald sie sich gezielt an Verbraucher innerhalb der Europäischen Union richten.
Was umzusetzen ist
Vier Anforderungen, ein Prozess
Ein Link auf ein PDF oder eine Kontaktseite genügt nicht. Erwartet wird ein durchgängiger digitaler Ablauf – einfach, transparent und nachvollziehbar.
Ein häufig übersehener Punkt: Mit der Funktion ändern sich auch die Pflichttexte. Widerrufsbelehrung und Datenschutzerklärung müssen angepasst werden – Letztere im Hinblick auf die neu erhobenen Daten, deren Verarbeitung und Speicherdauer.
Was viele falsch einschätzen
Plattform-Lage
Native Funktion oder maßgeschneiderte Integration?
Mit näher rückendem Stichtag entstehen überall Apps, Plugins und Erweiterungen. Das Bild ist je nach System unterschiedlich:
Eine native Plattformfunktion senkt die Einstiegshürde. Doch sobald ERP- und CRM-Anbindung, automatisierte Retouren und Rückerstattungen, individuelle Geschäftslogik, mehrsprachige Abläufe, Audit-Trails oder bestehende Kundenportale ins Spiel kommen, stößt eine Standard-App schnell an ihre Grenzen. Größere Shops und individuelle Lösungen brauchen Integrationen, die sich nahtlos in ihre Prozesse einfügen.
Auch wenn manche Details der nationalen Umsetzung noch konkretisiert werden, steht das Wesentliche fest: Der Widerrufsbutton wird Pflicht. Er ist kein isolierter Sonderfall, sondern Teil eines größeren Trends zu mehr Transparenz, Verbraucherfreundlichkeit und digitalen Standards im europäischen Handel. Wer seine Prozesse jetzt modernisiert, schafft nicht nur Compliance – sondern eine bessere Erfahrung für die eigenen Kunden.
So unterstützt Deepware
Nicht ein Button. Ein belastbarer Prozess.
Die Aufgabe besteht nicht darin, ein Element einzubauen, sondern einen rechtskonformen und technisch tragfähigen Widerrufsprozess zu schaffen. Wir bereiten Ihre Systeme rechtzeitig auf die neuen Anforderungen vor.
Revolutionierung großer Sprachmodelle durch die Mixture-of-Experts-Architektur
Im rasant wachsenden Umfeld der Künstlichen Intelligenz hat Tencent eine bahnbrechende Innovation vorgestellt: Hunyuan A13B. Dieses Open-Source-Sprachmodell markiert einen Paradigmenwechsel im Hinblick auf die Effizienz von KI. Es vereint die Leistungsfähigkeit von 80 Milliarden Parametern mit der Recheneffizienz von lediglich 13 Milliarden aktiven Parametern – dank seiner revolutionären Mixture-of-Experts (MoE)-Architektur.
Technische Spezifikationen
Das Modell verwendet eine ausgefeilte, fein abgestufte MoE-Architektur mit einem gemeinsamen Experten und 64 nicht-geteilten Experten, wobei bei jedem Forward Pass 8 Experten aktiviert werden. Es verfügt über 32 Schichten, SwiGLU-Aktivierungsfunktionen und Grouped Query Attention (GQA) zur effizienten Speichernutzung.
Alleinstellungsmerkmale
Leistungsvergleich
Visualisierung der Benchmark-Leistung
Zentrale Anwendungsfälle
Wettbewerbsvorteile
Effizienzvergleich
(Leistung pro Milliarde Parameter)
Zukünftige Auswirkungen
Hunyuan A13B stellt einen bedeutenden Fortschritt bei der Demokratisierung von KI-Technologie dar. Seine effiziente Architektur und der Open-Source-Charakter werden voraussichtlich:

Hunyuan A13B ist ein Beweis für die Leistungsfähigkeit innovativer Architekturen in der KI-Entwicklung.Durch die Kombination der Effizienz der Mixture-of-Experts-Architektur mit Dual-Mode-Reasoning und einem enormen Kontextfenster hat Tencent ein Modell geschaffen, das die herkömmliche Annahme infrage stellt, dass „größer immer besser“ sei.
Für Organisationen, die fortschrittliche KI-Funktionen ohne den hohen Rechenaufwand herkömmlicher großer Sprachmodelle implementieren möchten, bietet Hunyuan A13B eine überzeugende Lösung. Seine Open-Source-Natur in Kombination mit modernster Leistung positioniert es als echten Game-Changer in der KI-Landschaft.
Hunyuan A13B ist jetzt auf Hugging Face verfügbar und kann mit gängigen Frameworks wie Transformers eingesetzt werden. Schließen Sie sich der wachsenden Community von Entwicklerinnen und Entwicklern an, die dieses leistungsstarke Modell für innovative KI-Anwendungen nutzen.
Verwandlung von Text in filmische Realität mit nativer Audio-Integration
Die nächste Grenze der KI-Videoerzeugung
Im Mai 2025 stellte Google DeepMind Veo 3 vor – ein bahnbrechendes KI-Modell zur Videoerzeugung, das unsere Vorstellung von künstlicher Inhaltserstellung grundlegend verändert hat. Dieses hochmoderne System generiert nicht nur Videos – es erschafft vollständige audiovisuelle Erlebnisse, die die Grenze zwischen KI-generierten Inhalten und Realität verschwimmen lassen.
Wichtige Statistiken & Leistungskennzahlen
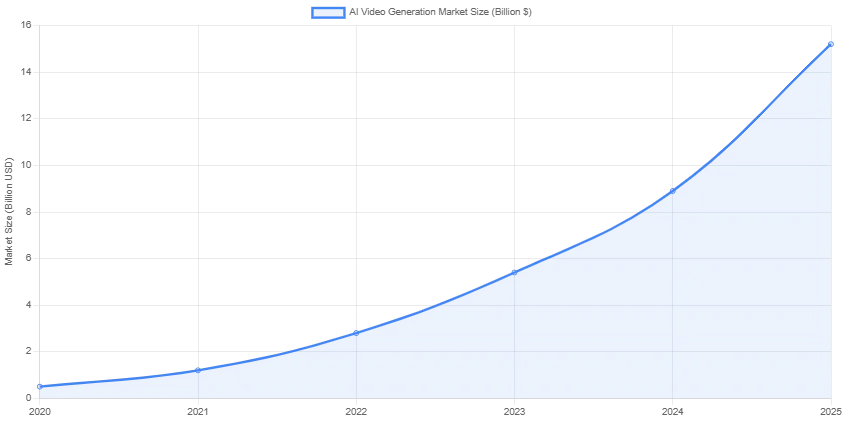
Entwicklung des Marktes für KI-Videoerzeugung
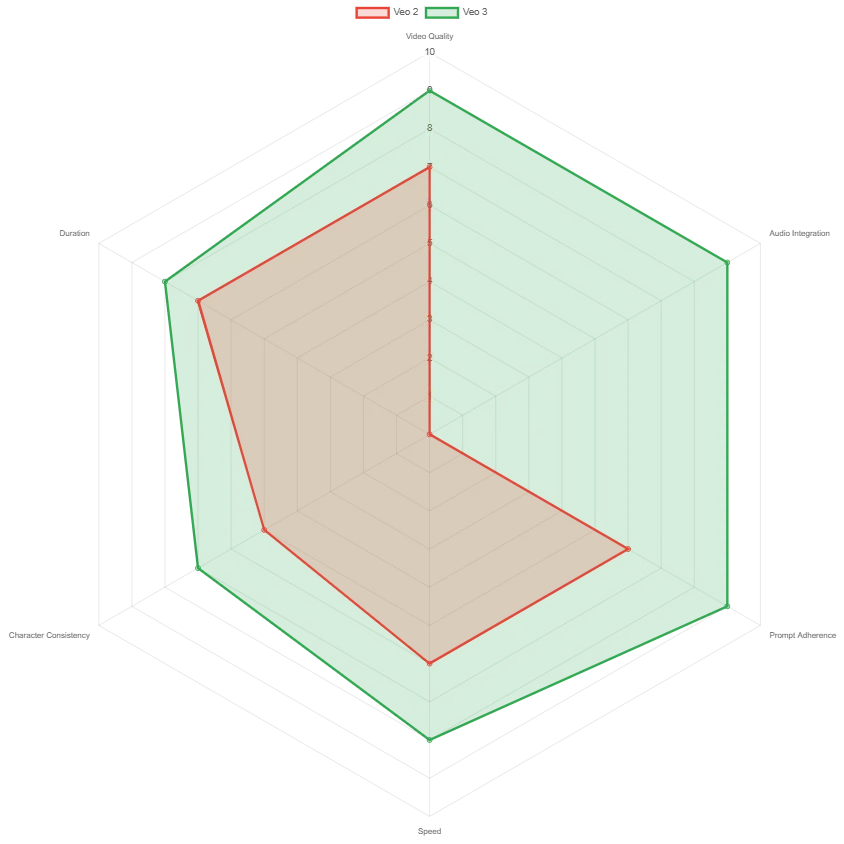
Veo-Modellvergleich: Zentrale Funktionen
Revolutionäre Funktionen
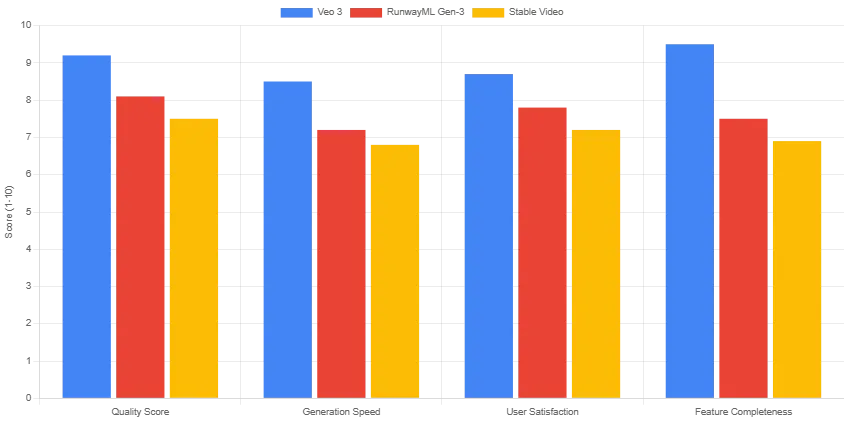
Leistungsbenchmarks: Veo 3 im Vergleich zur Konkurrenz
Technische Spezifikationen
Entwicklungstimeline
Vergleich der Google-AI-Tarife
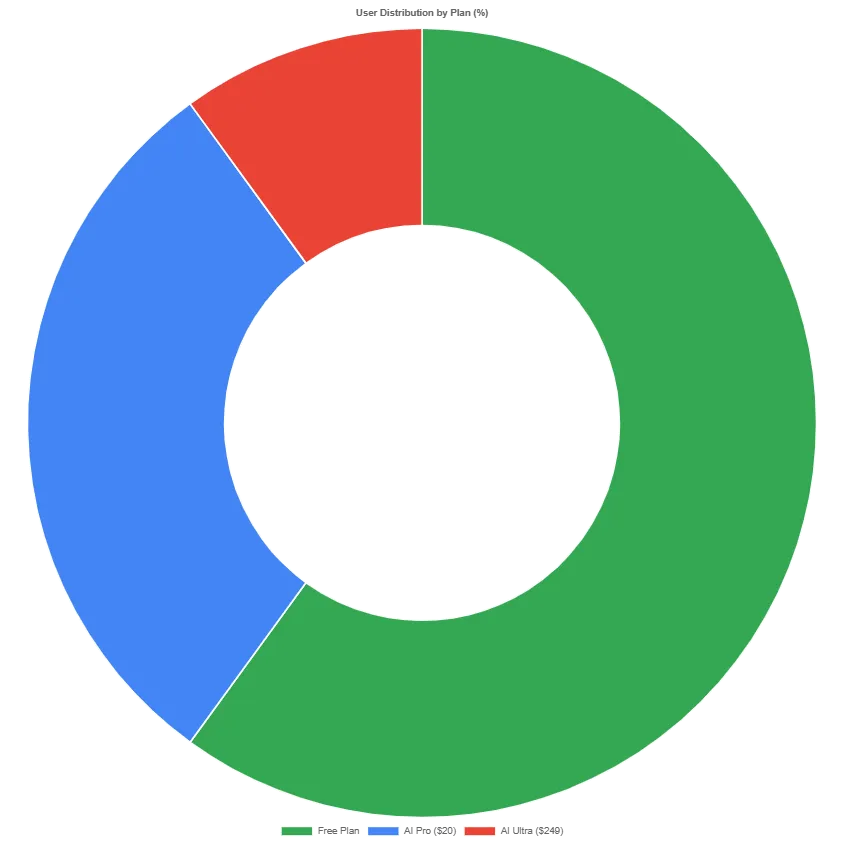
Tarifdetails

Nutzerakzeptanzrate (Erster Monat)
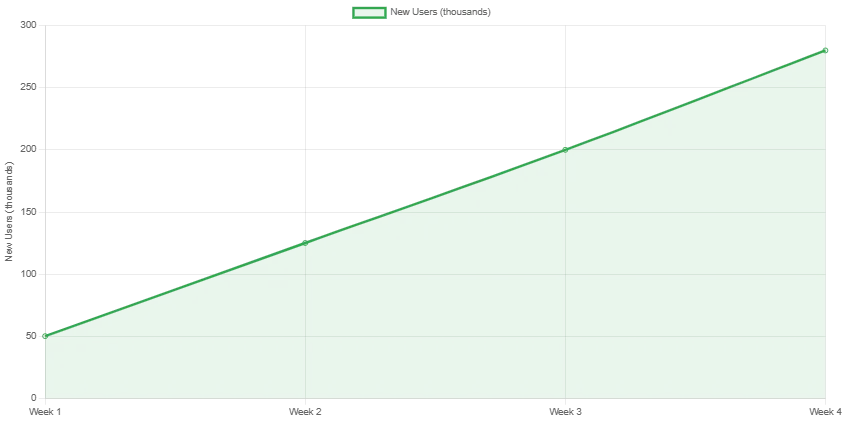
Die Resonanz auf Veo 3 war beispiellos im Bereich der KI-Videoerzeugung. Bereits innerhalb von nur drei Wochen nach dem Start hat das Tool:
- über 1 Million Videos in allen Nutzerstufen generiert
- eine Nutzerzufriedenheit von 85 % in der frühen Beta-Testphase erreicht
- die Videoproduktionskosten für kleine Content-Ersteller um 70 % gesenkt
- ranchenweite Diskussionen über die Echtheit und Regulierung von KI ausgelöst
Herausforderungen und Einschränkungen
Zukünftige Auswirkungen & Branchenrelevanz
Veo 3 ist mehr als nur ein technologischer Fortschritt – es markiert einen grundlegenden Wandel in der Erstellung von Inhalten. Die Integration nativer Audiogenerierung setzt einen neuen Branchenstandard, den Wettbewerber nur schwer erreichen werden.
Prognostizierte Veränderungen in der Branche:
- Demokratisierung der Inhaltserstellung: Hochwertige Videoproduktion wird für Nicht-Profis zugänglich
- Umbruch im traditionellen Mediensektor: Geringere Einstiegshürden stellen etablierte Produktionsfirmen vor Herausforderungen
- Regulatorische Reaktion: Regierungen werden voraussichtlich strengere Kennzeichnungspflichten für KI-generierte Inhalte einführen
- Bildungsrevolution: Personalisierte Videoinhalte verändern das Online-Lernen grundlegend
- Marketing-Wandel: Marken können unbegrenzt viele Varianten von Videoanzeigen erstellen
Fazit
Trotz bestehender Herausforderungen in Bezug auf Kosten, Zugänglichkeit und ethische Fragestellungen hat Veo 3 zweifellos den neuen Standard für KI-gestützte Videoerzeugung gesetzt. Die Frage ist nicht mehr, ob KI die Videoproduktion verändert – sondern wie schnell sich die Branche an diese neue Realität anpasst.
Die Zukunft der Videoinhaltserstellung ist da – und sie ist zugänglicher, leistungsstärker und realistischer als je zuvor.











.svg)




